Reverse-Engineering via Aqua Data Studio
You have the option of leveraging Aqua Data Studio to reverse-engineer your DDLs into the formats desired by Obevo.
- Obevo has been tested against version 12 of ADS
- For Sybase IQ, enable the Schema Grouping display for easy access, e.g. right-click your Server -> Server Properties -> Advanced Tab -> Object Folder panel -> set Schema Folder Groupig = Yes
To do this:
- In Aqua, go to Tools -> Schema Script Generator
- Choose all the objects that you want to include in the schema you want to include
-
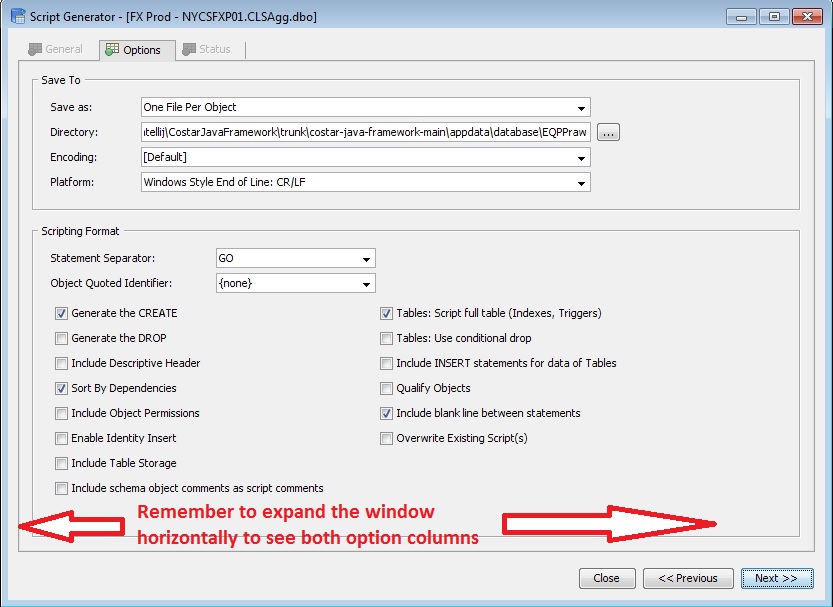
Choose the options for reverse-engineering as indicated in the Aqua Data Studio picture below
- NOTE #1 - if your Aqua Data Studio is not showing all the options there, you may need to expand your window horizontally and vertically (ADS quirk...). The screenshot below is from 7.0.39
- NOTE #2 - In Aqua Data Studio >= 8, the “Tables: Script full table (Indexes, Triggers)” seems to be disabled for some people. You can proceed anyway. (note - if you do have the option to choose it, do ensure that it is checked)
-
Use the DBREVENG command in the binary to rearrange files into the right format Here is an example - this will reverse-engineer the DB that was generated in the kata steps above. A sample output from Aqua Data Studio is provided in reveng-example
%OBEVO_HOME%\bin\deploy.bat DBREVENG -dbType DB2 -dbSchema YourSchemaName -mode schema -inputDir h:\reveng-example -outputDir h:\reveng-example-output
# note - for dbSchema, specify the DB2 schema, i.e. the ASE-equivalent of "database", i.e. IQ-equivalent of "schema", etc.
# Other optional args:
-nameCombinePattern "combinePattern" ==> Lets you combine multiple related tables (e.g. MYTABLE and MYTABLE_WRK) into one file for easier management. Specify the pattern like {}_WRK, where {} is the placeholder for your table (akin to the logging in slf4j)
-preprocessSchemaTokens "true/false" ==> Defaults to true; this will remove any explicit references to the default schema left in your Aqua output. Only set to false if you've already cleaned up those references.
# Deprecated args::
-tablespaceToken ==> Will add the string "IN ${schema_TABLESPACE}" at the end of your tables (helpful for DB2). Use the default instead, which simply removes the schema references instead of replacing w/ a token
- Regarding the output:
- This will generate the reverse-engineered output under <outputDir>/final
- If preprocessSchemaTokens is true (which it is by default), you will also see an <outputDir>/interim folder that has the output of the schema prefix removals.
- You should compare the input to the interim output to ensure that the basic schema removal was done correctly. If it wasn’t, you can manually correct the interim folder, and then rerun the reverse-engineering with “-preprocessSchemaTokens false”
- Once you have these files, do the final touches on them as you see fit (e.g. delete junk tables), and proceed to the next step
- Note the warning in your output - if you see any directories with a name containing “-pleaseAnalyze” in the result of the DBREVENG script, then the tool could not figure out what to do w/ those sql snippets. Either manually figure out where to put them and do so, or if you find too many such cases, reach out to the product team via Github, including a zip file of your reveng contents
Note that we explicitly don’t include the grants here. This is because you can & should use the global permissioning functionality instead
Once done, return to the Existing Onboarding Guide to continue the onboarding process

