

Obevo allows users to maintain their database scripts in an object-based structure, such as the structure below. This page describes how to implement this.
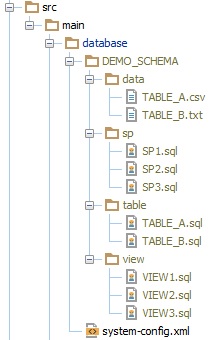
The system-config.xml file is the starting point of your db source code. Hence, the directory containing it is your db root folder
system-config.xml defines:
You can read the provided system-config.xml file for some of the features and configurations that you can define
A couple of the key configs to note (see the xml example for details):
You can define your DB connection in 3 different ways:
The dbSchemaPrefix and/or dbSchemaSuffix attributes can be used to add a prefix or suffix across your logical schemas when pointing to a particular environment
<!--schema override example -->
<dbSystemConfig type="DB2">
<schemas>
<schema name="SCHEMA1" />
<schema name="SCHEMA2" />
<schema name="SCHEMA3" />
</schemas>
<environments>
<dbEnvironment name="test" dbServer="example" ...>
<schemaOverrides>
<schemaOverride schema="SCHEMA1" overrideValue="my_schema1abc" />
<schemaOverride schema="SCHEMA2" overrideValue="my_schema2def" />
<!-- you don't have to specify an override if you don't want to, say for SCHEMA3 in this example. Then, it will just take the original value -->
</schemaOverrides>
...
</dbEnvironment>
</environments>
</dbSystemConfig>
By default, Obevo will refer to an object by its default catalog/database. For example:
We imply the schema user here (e.g. dbo - schema1.dbo.object1)
If you need to define your objects in a schema within the database, consider the following:
<!--schema override example -->
<dbSystemConfig type="SYBASE_ASE">
<schemas>
<schema name="SCHEMA1" />
<schema name="SCHEMA2" />
</schemas>
<environments>
<dbEnvironment name="test" ...>
<schemaOverrides>
<!-- note - many logical schemas can map to different schemas within the same database -->
<schemaOverride schema="SCHEMA1" overrideValue="mydatabase.myschema1" />
<schemaOverride schema="SCHEMA2" overrideValue="mydatabase.myschema2" />
</schemaOverrides>
...
</dbEnvironment>
</environments>
</dbSystemConfig>
CREATE TABLE ${SCHEMA1_subschemaSuffixed}myobject ( ... )
You can do more advanced environment management with Obevo, including tokenization, permission management, and environment-specific deployments.
See the Environment Management page for more information, though you should first understand the rest of this page and the DB project structure basics.
Underneath your root folder, you should define a folder for each of the logical schemas that you will maintain in this module.
For each schema, you will then define the table, sp, view, data, … folders
In some use cases, you may want to separate the directories in which your config and your schema folders reside.
It is worth going through the rest of this page first to understand the basics. But if you do want to explore separating your config and schemas, please see the schema-and-config-packaging page for more details.
Your table definitions will go under the table folder in the schemas
As mentioned in the intro doc, the goal here is to promote a db-object-oriented structure for your code base. Hence:
table/PRODUCT.sql table/ACCOUNT.ddl table/ENTITY.sql table/codes/NET_TYPE.sql table/codes/INSTRUMENT.ddl table/codes/PROD_TYPE.fx.abc.sql table/codes/PROD_TYPE.fi.abc.sql view/V_PRODUCT.sql view/V_ENTITY.sql sp/CREATE_PRODUCT.ddl data/codes/INSTRUMENT.sql data/NET_TYPE.csv
The only rules to consider here are:
In terms of what you are flexible with:
This applies for all object types
You can use the \${token} convention to replace tokens that you’ve defined in system-config.xml
Now we discuss the specific content rules for each of the object types
Stored procedures, views, and data are very easy to define in Obevo; but given that tables are focal point of databases, we will start there
Below is an example of a table file. We will describe below:
//// CHANGE name=chng1
CREATE TABLE TABLE_A (
A_ID INT NOT NULL,
B_ID INT NOT NULL,
STRING_FIELD VARCHAR(30) NULL,
TIMESTAMP_FIELD TIMESTAMP NULL,
PRIMARY KEY (A_ID)
)
GO
//// CHANGE name=chng3
ALTER TABLE TABLE_A ADD COLUMN C_ID INT NULL
GO
//// CHANGE name=chng2
ALTER TABLE TABLE_A ADD FOREIGN KEY FK_B (B_ID) REFERENCES TABLE_B(B_ID)
GO
//// CHANGE name=mytrigger
CREATE TRIGGER mytrigger ON TABLE_A
FOR abc123 ...
GO
//// CHANGE name=extra1
ALTER TABLE TABLE_A ADD COLUMN EXTRA1 INT NULL
GO
Basically, all alters on a table (including CREATE TABLE, ALTER TABLE, adding constraints, adding indexes, adding FKs or triggers) will go into this file
Each change for a particular release or functionality should be demarcated using the “//// CHANGE name=123” annotation
If you use the global permissions functionality, you do not need to define GRANT statements in your files! The tool will automatically execute these for you upon detecting a “CREATE TABLE” phrase (whitespace between CREATE and TABLE is taken care of)
Once a change is deployed to an environment, it cannot be modified or deleted.
(*) - For special cases (e.g. undoing a change deployed to UAT but not prod), a //// CHANGE can be removed with a special directive in the code. See the Rollback page for details.
Given that changes are immutable, can I drop a table and then remove a file? Yes, but with special directives. We do not want to just delete a file and have the table dropped, as we can’t foresee any cases of accidentally dropping or renaming a file; we want to be conservative in this case
Steps for dropping a table:
//// CHANGE name=chng1
CREATE TABLE TABLE_DROP (
ID INT NOT NULL,
PRIMARY KEY (ID)
)
GO
//// CHANGE name=drop DROP_TABLE
You have a couple options on renaming tables in Obevo
The migration SQL should be in a /migration change (described in the sections below), so that the object files remain clean
The changes will also need the dependencies attributes to ensure ordering of the files (see the subsequent sections for more information on migrations and dependencies)
### /table/OrigTable.sql
//// CHANGE name="init"
CREATE TABLE OrigTable (
Field1 int,
Field2 int
)
GO
//// CHANGE name="dropOld" DROP_TABLE dependencies="OldToNewTableMigration.migration"
### /table/NewTable.sql
//// CHANGE name="init"
CREATE TABLE NewTable (
NewField1 int,
NewField2 int
)
### /migration/OldToNewTableMigration.sql
//// CHANGE name="migration" includeDependencies="OrigTable.init,NewTable.init" INSERT INTO NewTable (NewField1, NewField2) SELECT Field1, Field2 FROM OrigTable GO
As of this version, doing this in Obevo is a bit clunky, as you won’t be able to delete the old file, and the new file would not have the DDL defined. Suggestions to work around this for now:
### /table/OrigTable.sql
//// CHANGE name="init"
CREATE TABLE OrigTable (
Field1 int,
Field2 int
)
GO
//// CHANGE name="dropOld" DROP_TABLE dependencies="OldToNewTableMigration.migration"
### /table/NewTable.sql
//// CHANGE name="init" dependencies="OrigTable.init" sp_rename 'OrigTable', 'NewTable' -- Note - sp_rename is specific for Sybase. May be different for other DBMS types; this is just an example.
This spans the following object types (and this would be the directory structure you’d apply for each)
| Object Type | Directory | Vendor-specific Note |
|---|---|---|
| Stored Procedures | /sp | |
| Views | /view | |
| Functions | /function | |
| Sequences | /sequence | |
| Triggers | /trigger | |
| User Types | /usertype | Only Sybase ASE and MS SQL Server |
| Rule | /rule | Only Sybase ASE and MS SQL Server |
| Default | /default | Only Sybase ASE and MS SQL Server |
| Packages + Package Bodies | /routinepackage | Only for Oracle |
| Synonyms | /synonym | Currently only for Oracle; other vendors will be supported later |
Here is an example:
CREATE PROCEDURE SP1 ()
LANGUAGE SQL DYNAMIC RESULT SETS 1
BEGIN ATOMIC
CALL SP2(2);
CALL SP2(3);
END
GO
That’s it! Just a matter of creating, editing, and deleting the file; just like Java. i.e.
Use “CREATE OR REPLACE” to create the object if your DBMS supports it, so that dependent objects do not have to be recreated as is needed for some DBs.
Likewise, if there are other syntax features of your DBMS (besides CREATE OR REPLACE) that you can use to create objects without recreating dependents, please do so. (See Redshift doc page for an example of this.
Do not define the “DROP PROCEDURE/VIEW/…” statement in your file. Obevo does it for you.
For cases where you have SPs of the same name, but different argument lengths, those should be defined in the same file
Obevo will take care of dropping each of the instances as needed
Some database objects, such as Oracle packages, are defined across two SQL statements: a declaration of the object signature, and its implementation.
The implementation can be more complex, esp. with referring to other objects, and so we would not want to force the two to be deployed in sequence.
Hence, we allow the file content to be split in two using the “//// BODY” line; the content preceding that line is the signature, and afterward the implementation body. See below for an example:
CREATE OR REPLACE PACKAGE MY_EXAMPLE_PACKAGE
AS
FUNCTION MY_FUNC1 return integer;
FUNCTION MY_FUNC2(var1 IN integer) return integer;
END;
GO
//// BODY
CREATE OR REPLACE PACKAGE BODY MY_EXAMPLE_PACKAGE
AS
FUNCTION MY_FUNC1
RETURN integer IS
BEGIN
RETURN 1;
END;
FUNCTION MY_FUNC2 (var1 IN integer)
RETURN integer IS
BEGIN
RETURN 1;
END;
END;
GO
A key tenet of Obevo is to not require excessive overhead on developers to define the order of db changes for every single change , e.g. via a sequence file or a versioning convention. It tries to be similar to application languages, e.g. Java, where users do not worry about the compilation order of classes within a module.
Obevo takes care of this by:
See the Design Walkthrough for more details on how this is done.
Specific steps on applying this to your code:
Order across all object types is inferred automatically based on the code of the object or CHANGE, except:
Note: cross-schema object dependencies cannot yet be inferred. Please use the explicit dependency specification for those use cases, described next.
To define the dependency explicitly, add the “dependencies”, “includeDependencies”, or “excludeDependencies” value to either the //// CHANGE line (for incremental changes) or //// METADATA line (for rerunnable objects)
The value is a comma-separated string that points to the dependencies of that change:
When to use each:
String format for each dependency is one of the following:
(Reminder: use the logicalSchemaName here - not the physical schema name)
Examples:
After the dependencies are declared, the changes are deployed respecting that order using Topological Sort. Apart from those mandated dependency orders, the sort order will break ties based on the following change types:
Given that the basis of Obevo is to handle a graph representation of the schema, it would make sense to be able to represent the schema objects in a graph format.
To enable this, use the -sourceGraphExportFile and -sourceGraphExportFormat arguments into the main deploy.sh client. The available formats are DOT (the default), GML, GRAPHML, and MATRIX.
Many systems store tables just for static/code data, not necessarily dynamic data.
For these cases, Obevo supports maintaining these as rerunnable files, such that if you wanted to add/modify/delete a row, you can just edit the file content in place, instead of having to specifically code to an incremental update statement.
These would go under the /staticdata folder in your schema (i.e. at the same level as /table, /sp, /view, etc.
Within that folder, you can use 2 methodologies for organizing your data, depending on which use case fits you better. (both can coexist within that folder and be used for different tables in the folder)
Here, we define a file per code table (i.e. the same paradigm that we use for the other objects in obevo, like tables/sps/views/etc.)
e.g. say we want to maintain static data for 3 tables, VIEW*DEF, VIEW*COLUMN, COLUMNDEF; the directory would look like this:
/myschema/staticdata /myschema/staticdata/VIEW_DEF.csv /myschema/staticdata/VIEW_COLUMN.sql /myschema/staticdata/COLUMN_DEF.csv
In terms of the actual content format of that file (i.e. how to represent the static data), you have two options:
See the example below; hence, every time you change this file, the script will be rerun (delete all, insert all)
This is a simple option and what you’d be used to if doing manual deployments; but if you want a nicer form of representation (or just don’t want to delete all your rows for a deployment), then try the CSV option…
DELETE FROM COLUMN_DEF GO INSERT INTO COLUMN_DEF (COLUMN_ID, COLUMN_NAME, ADD_TIME) VALUES (20, 'col1', '2012-01-01 12:12:12') GO INSERT INTO COLUMN_DEF (COLUMN_ID, COLUMN_NAME, ADD_TIME) VALUES (21, 'col2', '2013-01-01 11:11:11.65432') GO INSERT INTO COLUMN_DEF (COLUMN_ID, COLUMN_NAME, ADD_TIME) VALUES (22, 'col3', null) GO INSERT INTO COLUMN_DEF (COLUMN_ID, COLUMN_NAME, ADD_TIME) VALUES (50, 'txncol1', null) GO INSERT INTO COLUMN_DEF (COLUMN_ID, COLUMN_NAME, ADD_TIME) VALUES (51, 'txncol2', '2012-01-01 12:12:12') GO INSERT INTO COLUMN_DEF (COLUMN_ID, COLUMN_NAME, ADD_TIME) VALUES (52, 'txncol3', '2013-01-01 11:11:11.65432') GO
COLUMN_ID, COLUMN_NAME, ADD_TIME 20, "col1", "2012-01-01 12:12:12" 21, "col2", "2013-01-01 11:11:11.65432" 22, "col3", null 50, "txncol1", null 51, "txncol2", "2012-01-01 12:12:12" 52, "txncol3", "2013-01-01 11:11:11.65432"
Just define a CSV file (quotes are supported, as is changing the comma delimiter and null token) with the first row as the column names, and you are set.
By default, as shown above, the literal null (without surrounding quotes) is interpreted as the null value. If you wish to modify that, you can do so using the nullToken property in the METADATA header as follows:
//// METADATA nullToken="myNullToken"
If a change is done on the table, Obevo will only deploy the incremental change (it will compare the full dataset in the db table vs. the file and apply the appropriate insert/update/delete)
Note that there is reverse-engineering available to make this easy to onboard for existing projects (see the [existing-onboarding-guide](Onboarding Guide) for more details).
To manage a table as static data in Obevo, a unique key must be defined, whether physically on the table, or configured in code.
Specifically, either as: - (Preferred) An explicit primary key or unique index if one doesn’t exist already (this is a good practice to do anyway) - Or defining a metadata attribute as follows, in case you cannot physically define the constraint
//// METADATA primaryKeys="field1,field2" field1,field2,value a,b,11 c,d,22
Note that the PK or unique index is only considered if all of its columns are defined in the CSV (otherwise, Obevo would not be able to correctly compare results between the CSV and the actual database).
Note that if you do have a valid physical primary key or unique index on the table, then you are not allowed to define the metadata attribute as an override.
You can define certain columns as an “updateTimeColumn” if you’d like its value to be updated to the current timestamp when its row is either inserted or updated, per the example below.
//// METADATA updateTimeColumn="col1" ... field1,field2,value a,b,11
This column would not be specified in your CSV file.
Implementation note: the time value is set in Java and passed to the database via JDBC, and not as a “current timestamp” keyword in the DB implementation.
If you have tables that depend on each other via foreign key, you must use the CSV format (which is the preference anyway).
The reason here is that if you have inserts/updates/deletes spanning those related tables, the operations need to be done in the correct foreign-key dependency order.
For example:
Lucky for you, Obevo takes care of this!
Some use cases lend themselves towards representing static data not per table, but for a set of tables involving a particular context. For example, a set of tables that together represent metadata for some application, but the metadata definitions make more sense grouped from the user context and not the table context.
In those cases, your files may make sense to represent like this (taking the same content above, but represent it in the staticDataGroup mode)
### position-view.sql ### delete from view where view_id = 1 delete from column_def where column_id in (20,21,22) delete from view_columns where view_id = 1 insert into view (1, "position") insert into view_columns (1, 20) insert into view_columns (1, 21) insert into view_columns (1, 22) insert into column_def (20, "col1") insert into column_def (21, "col2") insert into column_def (22, "col3")
### transaction-view.sql ### delete from view where view_id = 5 delete from column_def where column_id in (20,21,22) delete from view_columns where view_id = 5 insert into view (5, "transaction") insert into view_columns (5, 50) insert into view_columns (5, 51) insert into view_columns (5, 52) insert into column_def (50, "txncol1") insert into column_def (51, "txncol2") insert into column_def (52, "txncol3")
Note that:
Though the file name is not strictly a “db-object” view at this point, it is still a rerunnable script and makes more sense from a maintainability perspective, so go right ahead and do it if it makes sense for your use case!
Note from the author to those who read this section for past versions: yes, this text has changed a lot :) - we now support ad-hoc data migrations, as we recognize that some teams are fine to do backwards-incompatible changes whereas others do not. Will explain more below.
Use this for one-time data migrations on your transactional tables (i.e. not the static data tables).
Note that these kinds of SQLs can easily be executed within the /table files themselves, as ultimately those just execute SQLs. In fact, the format of the /migration files is the same as the format of the /table files.
So when would you define the changes in /migration files vs. /table files?
Migrations in /table file?: Very simple backfills of newly added columns (e.g. the snippet below)
alter table TABLE_A add new column MYCOL GO update TABLE_A set MYCOL = 0 GO
Migrations in /migration file?]: some use cases:
{/table/TABLE_A.sql file}
//// CHANGE name="init"
CREATE TABLE TABLE_A (COL1 INT, COL2 INT, ...)
GO
//// CHANGE name="addNewCol2"
ALTER TABLE TABLE_A ADD NEWCOL2 (INT)
GO
//// CHANGE name="removeOldCol" dependencies="migration2.step1"
ALTER TABLE TABLE_A DROP COL2
GO
{/migration/migration2.sql file}
//// CHANGE name="step1" dependencies="TABLE_A.addNewCol2"
UPDATE TABLE_A SET NEWCOL2 = COL2 + 1
GO
1) Define the files in the /migration folder
2) File content is the same as for tables, i.e.
Differences from /table representation:
A) The file name need not correspond to a db-object name. You are free to name this as you please.
B) You are allowed to delete /migration CHANGE entriesafter being deployed . This is because we don’t want/need migrations lying around in the code, as they are one-time activities. Deleting the entries will UNMANAGE them from Obevo, akin to the UNMANAGE/delete operation with static data tables. i.e. if the migration file is deleted, the entry is removed from the audit table, and Obevo leaves the table untouched otherwise.